Woah, we’re halfway there…
We're halfway through the PXR Blind Challenge: unblinding the first data, freezing the leaderboard, and stepping into Phase 2 — plus a look at the response so far and what's next.
Living on a prayer (and half a test set): Unblinding the data, freezing the board, and stepping into Phase 2.
By Jon Swain, Maria Castellanos, Hugo MacDermott-Opeskin, and Pat Walters
We are halfway through the OpenADMET PXR Blind challenge! We have been overwhelmed with the response so far. Thank you all for participating! It's been incredible to watch you all duel it out at the top of the leaderboard while discussing constructively on Discord. Phase 1 has been everything we hoped and more.
That also means it's time for the halfway handover. Today we're doing two things: unblinding the Phase 1 data, and publishing a one-time interim leaderboard so you can see exactly where things stand before the board freezes for Phase 2.
It’s the end of Phase 1!
As a reminder of how the challenge is structured, the activity prediction track runs in two phases, deliberately designed to mirror the iterative nature of real drug discovery. Throughout Phase 1 (1st April – 26th May), we evaluated every submission against the full blinded test set, with the live leaderboard reflecting the performance on just one half (Analog Set 1). The other half, Analog Set 2, remained hidden.
Phase 1 is now closed. From here on, your job changes from predicting blind to responding to new information, the quintessential problem of drug discovery as practiced. The ground-truth pEC50 values for Analog Set 1 are now unblinded and available on our HuggingFace dataset (phase_1_unblinded). This is the new data you get to react to. We are excited to see what you make of it. Fold it into your training pipelines and predict on Analog Set 2!
We have also conducted more focused SAR exploration around some of our hits using high-throughput chemistry (HTChem). We are excited to release this to you as additional training data! This required us to develop an analytical chemistry workflow to correct the activity for the yield of crude and semi-pure compounds. Read more at our blog and dive into the data on the HuggingFace dataset (crudes_htchem and semi_pure_htchem). Your final standing will be decided in Phase 2 (26th May – 1st July), evaluated on Analog Set 2, the half of the test set that remains blinded. There will be no live leaderboard during Phase 2; submissions are scored quietly in the background, and the final leaderboard is released after the challenge closes at 11:59 PM UTC on 1st July. Because there was some confusion about the exact end of Phase 1 (mostly caused by us), the Phase 1 interim leaderboard will show your last entry before 11:59 PM PT on May 26th.
The structure prediction track remains unchanged, no data is unblinded, and the live leaderboard scored on the Phase 1 compounds will continue to update. The final leaderboard will be scored on the Phase 2 compounds.
Interim leaderboard (and the winner is … everyone)
Alongside the unblinding, we've published an interim leaderboard for the activity track on our HuggingFace space. This is not the live leaderboard you've been watching. The live leaderboard only ever scored Analog Set 1. The interim leaderboard takes each team's most recent Phase 1 submission and scores it against the full test set, both Analog Set 1 and Analog Set 2 combined. Think of it as a frozen, more complete snapshot of where everyone landed at the halfway mark. We also have the top 10 for the activity track shown below. Note that CLD is limited to the top 100 submissions for the activity track.
The statistical comparison of entries and compact letter display were calculated using the paired bootstrap with Holm-Bonferroni correction as detailed in this blog post. Because the scores for the top submissions are so close together, none of the top 10 were found to be statistically distinct. In fact, the letter d grouping from the compact letter display (CLD) spans the first 17 entries, and the letter a grouping reaches down as far as 30th position. A small number of entries in the top 10 (for example N283T in 4th and sia in 5th) have statistically significant differences in performance from entries lower down the list that were not observed for the other entries in the 10 top, which results in the complicated looking CLD we see for the top 10. When the variation in performance from bootstrap sampling (standard deviation averaging 0.02) is significantly larger than the difference between entries (averaging 0.002 for the top 10), CLD becomes a poor method for visualising this. The top 10 are currently separated by a hair’s breadth. This is a testament to the quality of the submissions; we aren't just seeing one dominant architecture, but a crowded field of high-performing models. For future iterations, we may consider tiered ranking systems. Instead of a long list of letters, we may group models into 'performance tiers' in which models within a tier are statistically indistinguishable from the leader of that tier. This provides a more robust view of model reliability than the alphabet soup of CLD with very similar entries.
The shift in rankings between the Live and Interim boards is telling. The Live board only saw Analog Set 1. Those who climbed the ranks in the Interim board (which includes the previously hidden Analog Set 2) are demonstrating true generalization. It suggests their models haven't just memorized the local SAR of the first set, but have captured more fundamental PXR-ligand interaction patterns that hold up across more diverse chemical space.
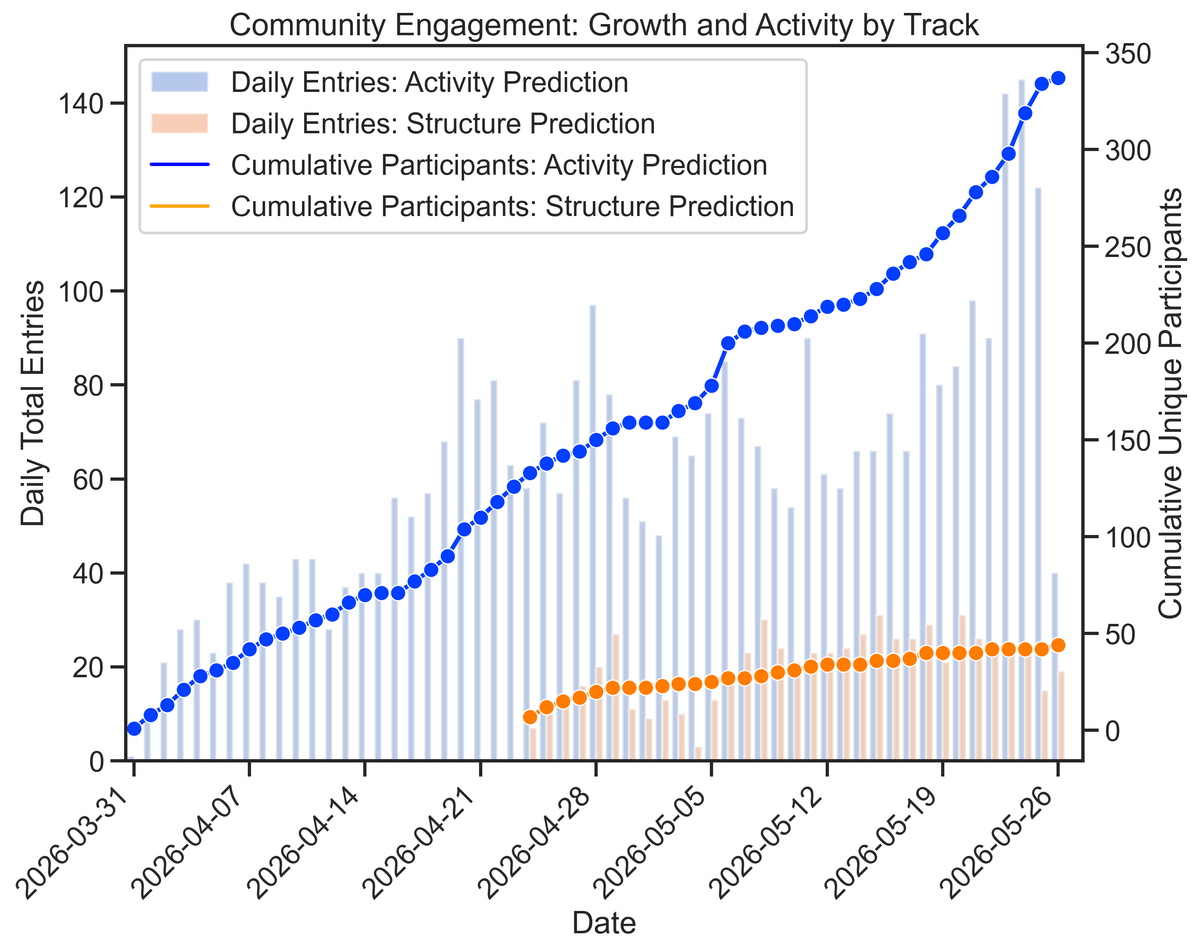
We’ve had over 300 unique participants for the activity challenge, and almost 50 for the structure prediction track. This only shows the structure entries from when the test dataset was finalised. The difference is likely driven by the difference in accessibility of the tasks. The Activity Prediction track saw dominant participation, likely because its tabular data format is more approachable for standard machine learning workflows compared to the specialized geometric deep learning or docking methods required for protein-ligand co-folding in the Structure track. Both tracks experienced a significant surge in daily entries this week as the Phase 1 deadline approached. This is especially visible in the Activity track, where daily submissions peaked at over 140 entries, reflecting an intense period generating final model predictions for the interim leaderboard by the community.
Get ready for Phase 2
As you gear up for Phase 2, please keep in mind that there will be no live leaderboard, allowing the suspense to build until the final results are revealed. When submitting your predictions, please continue to include all compounds, even those from the Phase 1 release, as this streamlines our scoring pipeline; however, rest assured that your final standing will be determined solely by your performance on Analog Set 2. You have until 11:59 PM UTC on July 1st to submit your final entries. To be eligible for the final leaderboard, you must include a comprehensive model report along with your accurate HuggingFace username. Furthermore, if you wish to be credited in future reports regarding this blind challenge, please ensure your contact information is complete and correct. Finally, we maintain a strict policy against using multiple aliases; any attempts to circumvent this policy may result in the removal of your entries at our discretion.