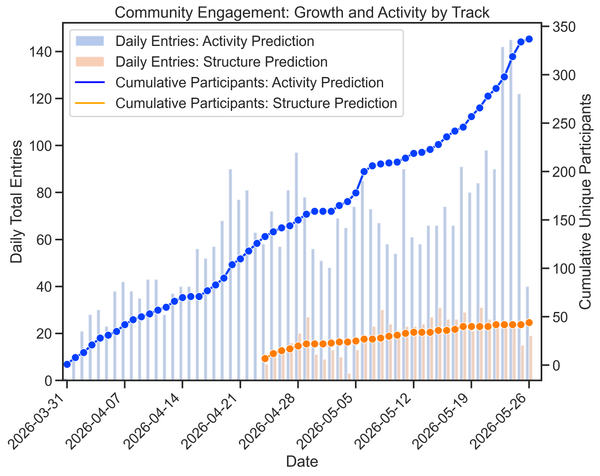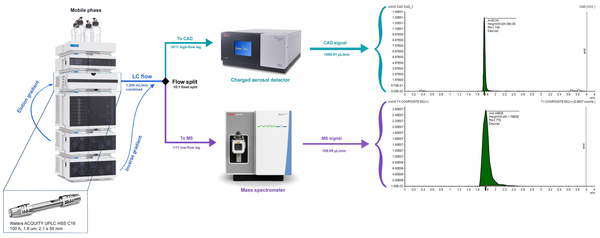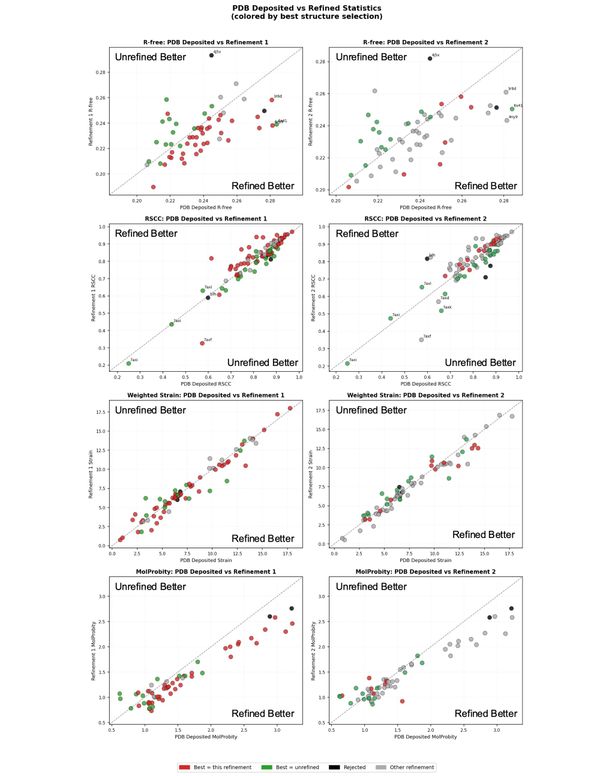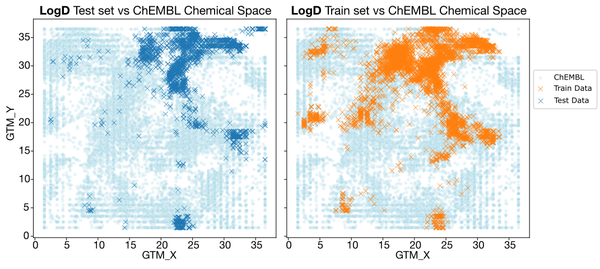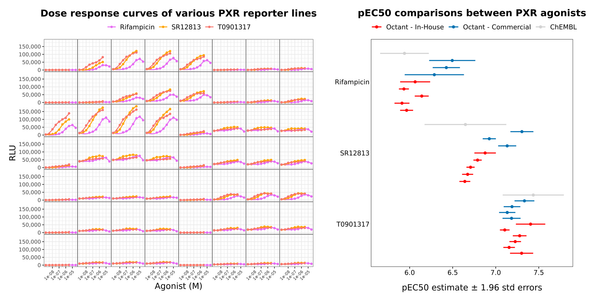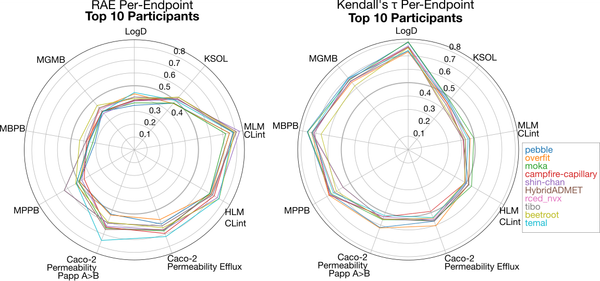
Not invited to the party? How to make proprietary ADMET insights more accessible
How do you train robust deep learning models when most of the high-quality data is proprietary? Discover how to enrich multitask ADMET predictions using a public proxy for proprietary learnings.